
XLNet은 Transformer-XL을 기반으로 구축된 모델입니다. 개인적으로 몇번 테스트 해봤을때, hyper-parameter에 매우 민감하며 permutation 과정 때문에 generation 성능이 좋지 않아, NMT로 확장하기 어려워 그리 좋아하지 않는 모델입니다. 하지만 엔지니어링 측면의 아이디어로서는 흥미로워 이렇게 포스팅을 씁니다.
총 포스팅은 3단계로 나누어 쓰고자 합니다.
- Transformer for Language Model
- Transformer-XL
- XLNet
이 포스팅에선 Language Model 에 대한 간략한 설명과 Language Model을 위한 Transformer의 구조(Masked Attention Mechanism), Transformer 모델의 한계에 대해 설명하고, 다음 포스팅에서는 Transformer-XL 구조와 XLNet에서 에 대해 소개해드리겠습니다.
Language Model?
Language Model이란 단어의 시퀀스의 확률을 예측하는 모델입니다. 예를 들어,
- 순서에 관계 없이 n 개의 단어로 이루어진 문장 W의 확률 값

- n – 1 개의 단어 리스트가 주어졌을 때, n 번째 단어의 확률 값

- 특정한 순서의 n 개의 단어로 이루어진 문장 W의 확률 값

위와 같은 확률을 예측하는 모델을 모두 Language Model 이라고 합니다. Language Model은 더 확률이 높은 문장을 예측하는 방향으로 모델이 학습되며 기계번역, 오타 검사, 음성 인식 등에서 활용됩니다.
Language Model in RNN
전통적으로 Language Model의 기본구조는 RNN이 담당하고 있었습니다. 예를 들어, 자연어 처리 분야에서 획기적인 성공을 거두고 있는 PLM(Pre-trained Language Model)의 초기 모델들인 TagLM, ULMFit, ELMo 등은 모두 Bi-LSTM을 기반으로 하고 있습니다. RNN은 이전 단어들을 순차적으로 계산하여 다음단어를 예측하기 때문에, (1) 속도가 상대적으로 느리며, (2) long-term dependency에 취약한 단점을 가집니다.

따라서, 병렬적으로 문장 처리가 가능한 Transformer가 RNN의 대체 모델로 제안 되기 시작했습니다. GPT를 시작으로 BERT, XLNet 등의 PLM 모델들이 Transformer의 decoder 혹은 encoder 를 변형하여 Language Model 에 적용하였습니다. 그 중에서도 여기에선 Transformer의 decoder를 변형한 버전을 소개해드리겠습니다.
Transformer는 문장 단어의 순서에 상관 없이 동시에 병렬로 처리하는 장점이 있습니다. 하지만, 그러한 점 때문에 Transformer를 Language Model에 적용하는 데 있어 처리할 문제들이 생깁니다.

- 입력 문장을 구성하는 단어의 순서 정보를 어떻게 모델에 전달할 것인가?
- 문장을 구성하는 단어 중에서도, 더 중요한 단어들을 어떻게 인지하고 처리할 것인가?
- 어떻게 단어를 병렬처리함과 동시에 이전단어들 만을 고려할 수 있을까?
답부터 말씀 드리자면, 위 세개의 물음에 대한 답은, 1. Position Encoding, 2. Attention Mechanism, 3. Masked Softmax 입니다. 이제 차근차근 자세히 설명드리도록 하겠습니다.
Transformer For Language Model
다시 한번 말씀 드리지만, 여기서 설명하는 Transformer는 “Attention All You Need” 논문에서 제안된 오리지널 Transformer의 Decoder를 변형하여 Language Model에 적용한 버전입니다.
전체 모델 구조는 다음과 같습니다.

1. Word Embedding
먼저 텍스트 형태의 단어를 vector로 변환하는 Word Embedding 과정을 거칩니다.

Word Embedding 과정은 기존 방식과 다르지 않습니다. 각 토큰의 index를 가지고 Embedding Matrix 에서 해당 index의 row를 뽑아내어 각각 토큰에 대한 embedding vector로 사용합니다.
2. Position Encoding
병렬처리에 의해 손실되는 단어의 순서 정보를 input에 추가해줍니다. 이를 Positional Encoding이라고 합니다.

이때 단어의 position은 sin과 cos값의 조합으로 나타냅니다. 모델에 따라서 Position Encoding 또한 word embedding 처럼 추가 matrix를 두고, 문장내 단어의 순서를 index로 하여 해당 index의 row vector를 position vector로 사용하는 경우도 있습니다. 이 때는 position embedding matrix를 모델과 같이 학습시킵니다.
3. Attention Mechanism
Attention Mechanism은 Transformer의 핵심 구조입니다. 특히 Masked Attention 구조는 Transformer의 decoder에서 사용되는 테크닉으로, 이전에 등장한 단어들만을 사용하여 다음 단어를 예측해야할 때 (즉, 이후에 등장할 단어에 대한 정보를 사용해선 안될 때) 쓰입니다. 물론 이것 또한 training 시에는 가능하지만, 이전에 등장한 output을 바탕으로 다음 단어를 예측해야 하는 test 시에는 masked attention을 사용해도 병렬 처리가 불가능 하겠죠.

오른쪽 그림은, 왼쪽의 attention 구조를 matrix로 표현한 것입니다. Transformer에서 사용하는 Attention 구조의 이름이 “Multi-head Attention” 인 만큼, attention은 여러개의 head로 이루어집니다. 오른쪽 그림을 보면 Query, Key, Value Matrix가 각각 h 개의 층으로 이루어져 있는데, 이 h가 head의 개수 입니다.
앞서 Word embedding에와 Position 정보를 가진 input 은 (max_sentence_length X embedding_dimension) 크기의 matrix 형태로 표현할 수 있겠죠. 여기에 각각의 weight matrix를 곱하여 query, key, value 값으로 변환 시켜 줍니다.

각각 Query, Key, Value 가 어떤 역할을 하는지 살펴봅시다. Query의 각 row는 기준이 되는 단어 입니다. 이 기준이 되는 단어들 각각에 대해, Key Matrix를 사용하여 문장 내의 단어들과의 관련도를 구합니다. 그리고 Query와 Key 를 사용하여 관련도를 구하였다면, 이 관련도를 Value에 곱하여 관련도가 높은 값은 크게, 관련도가 낮은 값은 작게 조정합니다.
좀더 자세히 살펴봅시다.

Query와 Key의 각각의 row는 문장 내의 각 단어들을 의미합니다. 그리고 두 matrix의 곱의 결과가 뜻하는 것은 이 각 단어들 사이의 관련도 입니다. 예를 들어, 두 matrix의 곱에서 (1, 2)의 값이 의미하는 것은 1번째 단어 “I”를 가지고 다음 단어를 예측 할 때 2번째 단어 “am”에 집중해야 하는 정도가 되겠습니다.
하지만 눈치 채셨듯이 여기엔 문제가 있습니다. 1번째 단어 “I”를 가지고 “am”을 예측해야하는데, 우리가 구한 Attention score에 이미 답인 “am”이 나와있습니다. 대놓고 답을 보여주는 식이죠. 이 문제를 해결하게 위해 아래와 같이 “Masked Softmax” 테크닉을 이용합니다.

Query와 Key를 사용하여 구한 Attention Score에 자기 자신 이후의 값들을 모두 Masking 해줍니다. 그 후에 softmax로 남은 값들을 Normalize 합니다. 이렇게, 이전 단어들만을 고려하여 Attention weight을 구하면 최종적으로 Value Matrix에 적용합니다.

Masked Attention 덕분에, 최종 Output의 각각의 row는 모두 이전 단어들에 대한 정보만을 포함할 수 있습니다. 예를 들어, 3번째 row는 “I am so” 3개의 단어 정보를 포함하고, 이 값으로 다음 단어 “cute”를 예측하게 됩니다.
이 계산을 head 마다 적용합니다. 그래서 총 h 개의 결과 값이 나오게 됩니다.
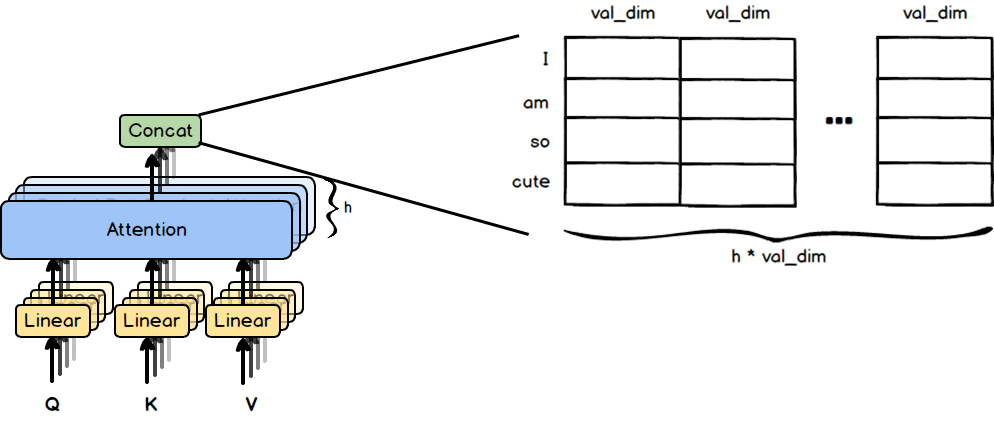
Attention을 적용한 총 h개의 matrix를 Concatenate 해준 후,

Linear Layer를 거쳐 input과 똑같은 dimension으로 맞춰 줍니다. 이렇게 input과 output의 dimension 구조가 같은 특징은 이후 layer 추가 등의 계산을 용이하게 합니다.
4. Layer Normalize & Position-wise FF
앞서 말했듯이, Multi-Head Attention Layer를 거치고 나서도 dimension이 동일하기 때문에, 몇 개의 layer를 거쳐도 dimension이 변화하지 않게 됩니다.
Multi-head Attention layer의 output에 input을 더해주고 Normalize 해준 후, 간단한 Feed Forward Network를 거쳐 Layer의 최종 output을 냅니다. 그리고 이 과정을 Layer의 개수만큼 반복합니다.

5. Calculate the probability of next word
마지막 Layer의 output에 다시 Linear Transformation으로 (max_sentence_length X vocab_size) 의 Matrix로 변환한 후 softmax를 취해줍니다.

이로써, output의 각 row가 의미하는 바는 이전 단어들이 주어졌을 때, vocabulary 내에서 다음으로 나올만한 단어를 확률의 형태로 보여줍니다.
6. Simple scheme
다시 한번 Language Model을 위한 Transformer의 전체 구조입니다. 모델을 간단하게 오른쪽과 같이도 표현합니다.

7. Problem of Transformer
다만, Transformer에도 문제점이 있습니다. 단어들을 병렬 처리한다는 특징 때문에, 입력 문장의 단어들을 순차적으로 입력이 불가능하고, 따라서 매우 긴 텍스트는 여러게의 segment로 잘라서 처리할 수 밖에 없다는 것입니다.
아래와 같이 특정 문장과 매우 밀접한 관련이 있는 문장이 이전 segment에 속해 있다면, 두 문장 간의 관련도를 계산하기는 불가능 하겠죠.

따라서 이를 보완하기 위해 등장한 것이 Transformer-XL 입니다.
Transformer-XL (eXtra Long)

Transformer-XL에서 주목해야할 것은 두가지 입니다.
- Positional Encoding → Relative Positional Encoding (+ Encoding 위치 변화)
- Memory Layer 추가
Transformer-XL에서 추가된 위 두가지 기법은, 후에 변형되어 XLNet에도 적용됩니다.
Transformer-XL의 자세한 구조는 다음 포스팅에서 다루도록 하겠습니다.
Reference
[1] DAI, Zihang, et al. Transformer-XL: Attentive language models beyond a fixed-length context. arXiv preprint arXiv:1901.02860, 2019.

댓글 남기기